
Research Data Management (RDM) means taking care of your research data in an organized and responsible way throughout the entire data life cycle. Well-managed research data follows the FAIR Data Principles, meaning others should be able to understand your data and reproduce your results. Effective RDM helps your project meet legal, ethical, and funding requirements while ensuring that research outputs remain discoverable, reusable, trustworthy, citable, and protected for the long term.
Email the Data and Visualization Librarian, Siti Lei (siti.lei@dukekunshan.edu.cn) for support with RDM, data management plan (DMP) creation, and data deposit.
Visit Office of Research Support (RSO) at DKU for support with research applications and funding opportunities.
Research data is the information collected, observed, generated, or created for the purpose of analysis and the production of original research results, together with any associated documentation, code, or scripts. Research data can be digital and analog, and includes both primary data created by researcher(s) and secondary data (obtained from other sources, such as census datasets or materials produced by other researchers).
For yourself and your project:
There are also practical reasons:
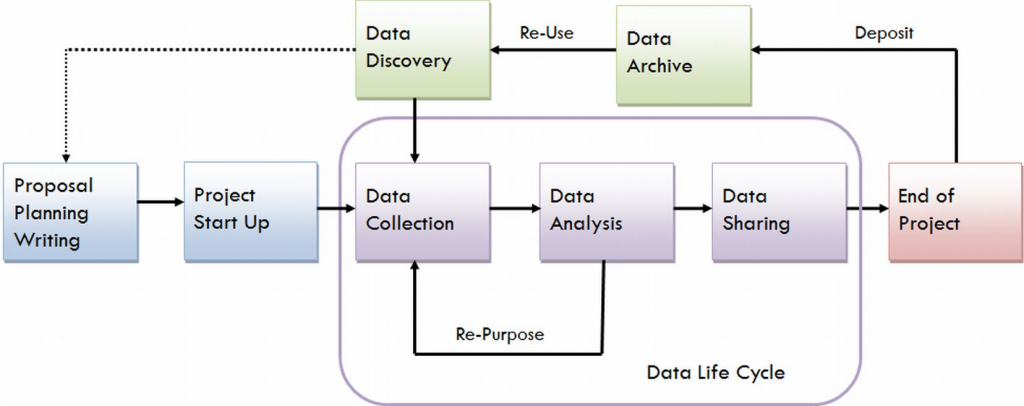
Best practices for RDM involve the entire data lifecycle, from the start to the end of a project. The main stages include Create, Store, Use, Share, Archive, and Destroy, each governed by applicable policies, rules, laws, and regulations that ensure ethical and responsible data handling.
The lifecycle of research data does not end when a project concludes. Instead, researchers are responsible for guiding data through stages of long-term preservation and potential reuse, ensuring that data remain accessible, secure, and valuable beyond the original study.
* Image courtesy of the University of Virginia Library Research Data Services + Sciences, http://data.library.virginia.edu/data-management/lifecycle
* Refer to Data Security and Storage by DKU Research Support Office.
Data Management Plan (DMP) is a document that plans out how research data is to be generated, managed, shared and stored during the entire research period from its implementation to after its completion. Funding agencies, research institutions, and journals often require a DMP to ensure that data are well-organized, secure, and reusable. Researchers should manage research data in accordance with the DMP to ensure responsible stewardship and future reuse.
The Office of Research Support at DKU provides Data Management Plans guidance to assist researchers in creating an effective DMP.
Recommended tools for creating a DMP:
For assistance with developing a DMP, contact Data and Visualization Librarian, Siti Lei (siti.lei@dukekunshan.edu.cn)
Submit your completed DMP to the Office of Research Support (research-support@dukekunshan.edu.cn)
Research group procedures (aka ‘lab procedures’, ‘standard operating procedures’) set expectations for working in collaborative research environments. They vary by group but typically cover policies (e.g., data ownership, confidentiality), workflows (e.g., file naming, version control), roles and responsibilities, use of space and equipment, approved tools and software, and general research and data management practices.
They differ from a DMP as they define how collaboration and data stewardship are organized across multiple projects, while a DMP is project-specific, detailing how data will be collected, stored, shared, and preserved in alignment with those procedures.
Establishing and documenting onboarding and offboarding procedures is essential for all research groups and collaborative projects. These procedures should include clear actions related to research data to standardize knowledge transfer and ensure that all team members have appropriate access to information, systems, and files. Effective procedures help reduce the risk of data loss or mishandling and ensure compliance with institutional and data security standards.
Onboarding procedures for research data may include:
Offboarding procedures for research data may include:
Ethical responsibility is essential to research. Consent and ethics safeguard participants, ensure that data is collected accurately and lawfully, and foster trust in research outcomes. At DKU, researchers should plan for consent and ethical approval before beginning data collection to ensure compliance with institutional policies, Chinese regulations, and responsible data management practices.
Things to consider before data collection:
Contact Institutional Review Board (IRB) to review and approve your research’s ethical protocols.
Instead of storing data and files in default computer locations (e.g., Desktop or Downloads), you should create separate folders to organize them by category.
Your folder directory structure should prioritize clarity and easy discoverability. Keep it simple – limit the structure to no more than 4 levels and 10 or fewer subfolders within each level.
Organizing your research files in a clear and consistent way makes your data easier to understand, share, and keep safe for the long term. It also saves you time when you need to find or reuse your files later. A good system should be descriptive, well-structured, and used consistently, with clear documentation explaining how the data was created, collected, and processed, as well as any information needed to help others interpret and reuse it accurately.
Examples of data documentation include:
Recommended tools for creating data documentation:
Tips for naming folders and files:
File formats is important for long-term data preservation and accessibility. Whenever possible, use open, non-proprietary, and widely supported formats (e.g., CSV, TXT, TIFF, or XML) rather than proprietary ones (e.g., Excel .xlsx, SPSS .sav, or Photoshop .psd) that may require specific software to open.
Open formats increase the likelihood that your data can be accessed, shared, and reused in the future. In the meanwhile, it is also helpful to document the file formats used in your project and explain any software dependencies.
When proprietary formats are unavoidable, consider saving an additional copy in an open or standardized format for preservation.
Version control helps you track changes to your data, documents, and code over time, ensuring that earlier versions can be recovered if needed. Clear version control practices help facilitate accuracy, reproducibility, and accountability throughout the research process.
When designing a file naming system, consider including version numbers or dates in filenames (e.g., 20251013_InterviewData_v002.csv), and maintain a change log or brief note describing what was modified in each version.
Tips for data backup:
Consider using following storage options:
For assistance with additional storage space for research data, contact the Office of Information Technology (IT) at DKU.
Understanding the risks associated with your data can help you adequately protect it. This is important for:
Check out DKU Data Security and Storage for guidance on identifying data classification level and storage requirement based on their sensitivity, confidentiality levels, and relevance to human subjects.
Sensitive data refers to information that, if disclosed, could cause harm to individuals, organizations, national security, or society.
Confidential data refers to any information that subjects to legal or contractual obligations to be kept private or restricted to authorized individuals or parties entrusted to safeguard them from unauthorized access, misuse, disclosure, modification, loss, or theft.
Human data refers to information obtained from or about individuals, communities, and groups. Human data may be considered sensitive and/or confidential and may be subject to specific ethical, legal, and contractual obligations.
In addition to the data you create yourself, you can explore the following sources to find secondary or third-party datasets:
Check the Office of Information Technology (OIT) and DKUL’s Tools and Software for available resources.
If you plan to use a campus computer, check out Public Devices and Data and Visualization Studio for information.
Be mindful of uploading research data to open AI tools, which carries the risk of exposing unpublished or confidential information and may be retained into the AI’s training model without the researcher’s permission. Sensitive and personal data should never be uploaded to or exposed through such AI tools.
Check out DKU AI Literacy: Policies & Guidelines for more information.
You’ve completed your project! Now what should you do with all the data?
Note: Before sharing your research data with others or depositing your research data to a repository, check with the Office of Research Support(RSO) to ensure safe and compliant submission with national laws and policies. In some cases, you may be required to de-identify or destroy your data, especially when it involves sensitive or confidential information.
As researchers at DKU, individuals are responsible for understanding and complying to the national laws and institutional policies of both China and the U.S. that regulate research data management and cross-border data exchange.
The Cyber Security Law of People’s Republic of China (CSL) is a foundational regulation that ensures network security, protects national sovereignty in cyberspace, and safeguards the rights of citizens, organizations, and the public interest. It promotes the secure development of China’s digital economy by establishing systems for network security classification, user information protection, and critical information infrastructure management.
The Personal Information Protection Law of the People’s Republic of China (PIPL) is a special law that aims to protect the rights and interests of personal information, standardize personal information processing activities, and promote the rational use of personal information. It designs a system for the entire process of personal information processing, puts forward strict requirements for the protection of sensitive information and cross – border provision of personal information, and clarifies the rights of individuals and the obligations of processors.
The Data Security Law of the People’s Republic of China (DSL) is a fundamental law governing data processing and protection in China. It aims to ensure data security, promote lawful data use, and safeguard national sovereignty and public interests. The law introduces systems for data classification, risk assessment, security review, and incident handling to protect the rights of individuals and organizations while supporting secure data development and utilization.
The Provisions on Facilitating and Promoting Cross-Border Data Flow aims to balance data security with international data exchange. It establishes guidelines for data classification, requiring critical data to be stored domestically while allowing non-sensitive data to flow across borders. Companies must conduct risk assessments, implement security measures, and obtain user consent for data transfers. The provisions encourage international cooperation, streamline compliance procedures, and promote data-driven innovation. It also emphasizes protecting personal information and ensuring transparency in data processing. Overall, the framework seeks to foster global digital trade while safeguarding national security and individual privacy.
The Common Rule (45 CFR 46) is the main U.S. regulation governing research involving human subjects. It protects participants’ rights, welfare, and privacy through ethical standards for data collection, storage, and use. The rule requires Institutional Review Board (IRB) approval and informed consent, ensuring that identifiable and sensitive data are handled responsibly and securely in federally funded research.
The Data Management and Sharing Policy by the Natural Institutes of Health (NIH) sets national standards for managing, preserving, and sharing research data. It requires all NIH-funded researchers to submit a Data Management and Sharing Plan (DMSP) outlining how data will be documented, protected, and made accessible. The policy promotes transparency, reproducibility, and alignment with open science and FAIR data principles.
The Federal Information Security Modernization Act mandates strict security standards for information systems managed by federal agencies and contractors. It establishes a framework for protecting data confidentiality, integrity, and availability through risk assessments, access controls, and regular monitoring. FISMA ensures that research projects involving federal data or funding comply with federal cybersecurity and data protection requirements.
Data repositories are online platforms that store, organize, and preserve datasets, often making them available for sharing and reuse. They are widely used by research communities to share and discover data.
There are three main types of data repositories:
Understanding copyright and licensing helps define how your data can be shared and reused. Always include a license statement in your metadata or README to clarify permissions and restrictions to your users.
